고정 헤더 영역
상세 컨텐츠
본문
충돌에 대해서 다시한번 정리하자면
특정 알고리즘을 가지고있는 해시함수를 통해 index값을 정하는데 있어서
서로 다른 값 들이 같은 해시함수를 통해 같은 값이 나오는 것이다.
오늘은 이 충돌을 회피 하기 위한 방법에 대해 알아볼 예정이다.
Chaining

그림을 확인하자면 " [여기 확인] " 을 보면 된다.
85라는 값을 Insert 했는데 Collision 이 일어낫고 Add to Chain 했다.
그림을 보고 유추 할 수 있지만 하나의 Index 값에 여러개의 값을 Chain형태로 저장을 하는 것이다.
즉, 한 Index 공간에 저장할 수 있는 값을 제한하는 것이 아닌
LinkedList 로 만들어 계속해서 Key 값을 추가 할 수 있다.
하지만 연결된 Index한 공간을 통해서 키를 저장하기 때문에 체인의 캐시 성능이 떨어지고
일부 해시테이블 공간이 사용되지 않아 공간 낭비가 있을 수 있으며
체인이 길어지는 경우 >> 검색 시간이 O(n) 이 될 수도 있습니다. - 최악의 경우
그래서 보통
얼마나 자주 Insert Delete 될지 예측할 수 없을 때 주로 사용된다.
그러면 성능은 어떨까?
해시 테이블의 공간 갯수 : M
해시 테이블에 삽입될 Key의 갯수 : N
부하율 : A ( = N / M )
기대 검색(Search) 시간 : O( 1 + A ) - 최악의 경우 O(N)
기대 삭제(Delete) 시간 : O( 1 + A ) - 최악의 경우 O(N)
삽입(Insert) 시간 : O(1)
검색(Search) 및 삭제(Delete) 시간 복잡도는 O(1) 이다. ( 만약 A(부하율) == O(1) 일 경우 )
Open Addressing
Chaining 과는 다르게 한공간에 하나의 key값만이 저장된다. 때문에 메모리 낭비가 초래되진 않지만
해쉬충돌이 일어날 가능성이 있어 알고리즘 설계를 잘 해야한다.
이 알고리즘 설계를 위해 대표적으로 3개의 방법이 존재한다.
- 선형탐색 - Linear Probing
- 제곱탐색 - Quadratic Probing
- 더블해싱 - Double Hashing
Open Addressing - 선형탐색 Linear Probing
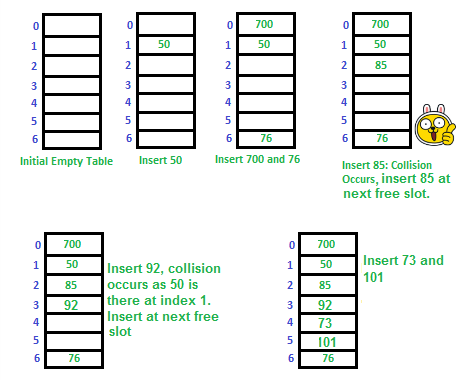
스티커 붙은 곳을 보면 85를 Insert 할 경우 Collision이 발생했고 85를 다음 Index인 2에 저장했다.
선형 탐색에서 해시테이블은 해시의 원래 위치(충돌이 일어난 곳)에서 순차적으로 검색된다.
즉, 이미 공간이 점유되어 있다면 다음 칸을 탐색 하는 것이다.
단점으로는
Primary Clustering - 해시 함수 이후 일어난 충돌을 해결함에 있어 다음 Index 공간들이 연속적으로 점유되어 있어
긴 실행 시간을 가지는 경우
쉽게 말해, 다음 Index도 다다음 Index도 다다다음 Index도 ... 이미 점유되어있는 상태다.
때문에 빈 공간을 찾거나 값을 검색하는데 있어서 시간이 계속해서 걸리기 시작한다.
Secondary Clustering - Primary Clustering 과 거의 동일하지만 연속적으로 붙어있는 Index가 아닌 서로 떨어져있는 Index에서 발생하는 클러스팅이다. 다음에 설명할 제곱탐색에서 자주 발생하는 문제인데
제곱 탐색 뿐만 아니라 선형 탐색에서도 문제를 일으킨다고 한다. 솔직히 정확하게 이해하지 못했다.
Open Addressing - 제곱탐색 Quadratic Probing
제곱 탐색은 조금 다른 사진을 보고 이해하는 것이 빠르다.

만약 Index 7번으로 값이 들어왔을 때 이미 점유가 되어있다면
첫번째 이동 : 1*1
두번째 이동 : 2*2
세번째 이동 : 3*3
.
.
.
n번째 이동 : n*n
이런식으로 탐색을 하는 것이다.
즉, 탐색에 비례하여 탐색 간격이 증가한다.
제곱 탐색은 우리가 위에서 논했던 Primary Clusering 문제를 해결 할 수 있다.
하지만 Secondary Clustering 문제는 여전하다.
Open Addressing - 더블해싱 Double Hashing
최적화된 클러스팅을 줄이는 방법이라고 할 수 있다.
말 그대로 탐색 순서에 따라 다른 해싱을 적용하여 중복을 줄이는 방식이다.
잠깐 복잡하니 집중 하자.
예를 들자면
Hash1(key) / Hash2(key) 가 있다고 가정한다. 다른 해싱을 적용해야하기 때문에 해싱 함수가 2개라고 가정한다.
그리고 각각의 해쉬함수를 통해 값을 계산하고 해당 값을 끼리 또 새로운 수식으로 최종 Index값을 계산한다.
ex )
- Hash1(key) = key % 13
- Hash2(key) = 7 - ( key % 7 )
- 최종 Index 값 계산 수식 : [ Hash1(key) + i * Hash2(key) ] % TableSize
여기서 i는 중복이 된만큼 증가한다.

그림을 보면서 확인해보자
만약 충돌이 일어나지 않았을 경우 Hash1(key) 를 사용해서 Index값을 설정한다.
중요한 부분은 Hash1(10) 의 값이 이미 점유되어있는 Index=10 의 값이다 .
여기서부터 계산이 시작된다.
- 최종 Index 값 계산 수식 : [ Hash1(key) + i * Hash2(key) ] % TableSize
자.
Hash1(10) = 10 ,
Hash2(10) = 7 - (10 % 7) = 4 ,
최종 Index 값 계산 = (10 + 1*4 ) % 13 = 1 <<< 여기서 충돌 i값 증가로 재 계산
최종 Index 값 계산 = (10 + 2*4 ) % 13 = 5
따라서 key값이 10일 경우 해시값은 5 이다.
'Database' 카테고리의 다른 글
| 데이터 베이스 커넥션 풀(Database Connection Pool) (0) | 2022.09.24 |
|---|---|
| 데이터 접근 기술 - JDBC (0) | 2022.09.21 |
| h2 [Error creating bean with name 'dataSourceScriptDatabaseInitializer'] (0) | 2022.09.16 |
| Hash (0) | 2022.08.05 |
| database [index] (0) | 2022.07.29 |





댓글 영역